1. 常用CUDA关键字
函数修饰词
__global__:修饰的函数只能返回void类型,并且函数在CPU端调用,在GPU端执行__device__:在GPU端调用并执行__host__:在CPU端调用并执行
变量修饰词
__global__:修饰的变量将存储在GPU的全局内存区域,Nvidia GPU内存模型详见下部分__shared__:修饰的变量将存储在线程块的共享内存区域
内置变量
dim3:cuda内置的结构体类型,其成员变量包含三个unsigned int,用于描述三维向量上三个维度的大小,使用时1
dim3 grid_dim(num1, num2, num3);
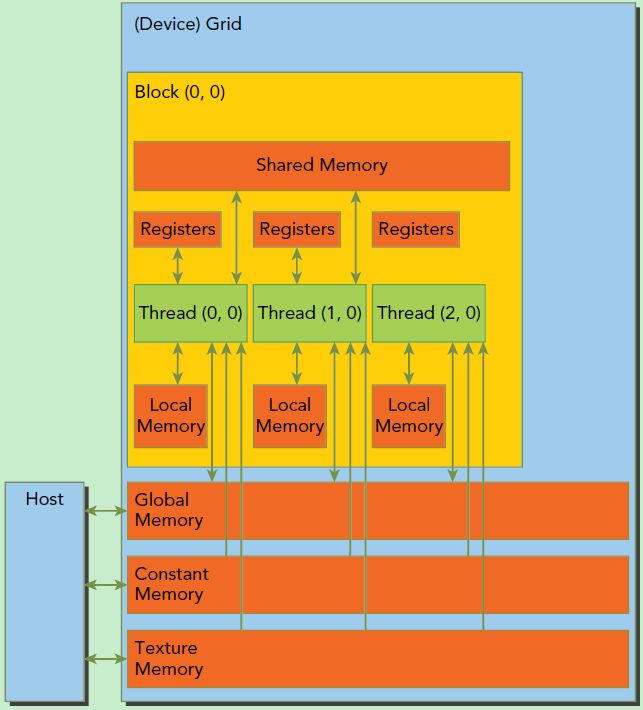
2. CUDA内存模型
CUDA代码运行的GPU中,其线程模型可以分为以下几个层次,由上及下依次为从小到大的包含关系
threads:GPU执行指令的基本单位,其布局在线程块block中用dim3类型的block_dim描述block:线程块,用于容纳若干线程(线程布局在调用__global__函数时,在<<< , >>>中定义),其在网格grid中的布局用dim3类型的grid_dim描述grid:网格,用于容纳若干线程块,同样在调用__global__函数时在<<< , >>>中定义
而cuda代码运行的内存模型有以下几类
registers:线程专有,为不带修饰词的变量使用local memory:局部内存,和寄存器一样为线程专有shared memory:每个线程块block专有的共享内存,线程块内所有的线程共享这片内存global memory:每个grid都有自己的全局内存,为每个block的所有thread共有constant memory:常量内存,为grid所有,只读texture memory:纹理内存,为grid所有,只读。是cuda主要针对2D数据访问优化的全局聂村区域
3. 规约算法
规约,是指对输入的N个元素进行满足结合律的运算,其特点是各元素之间的结合计算顺序不影响最终计算结果
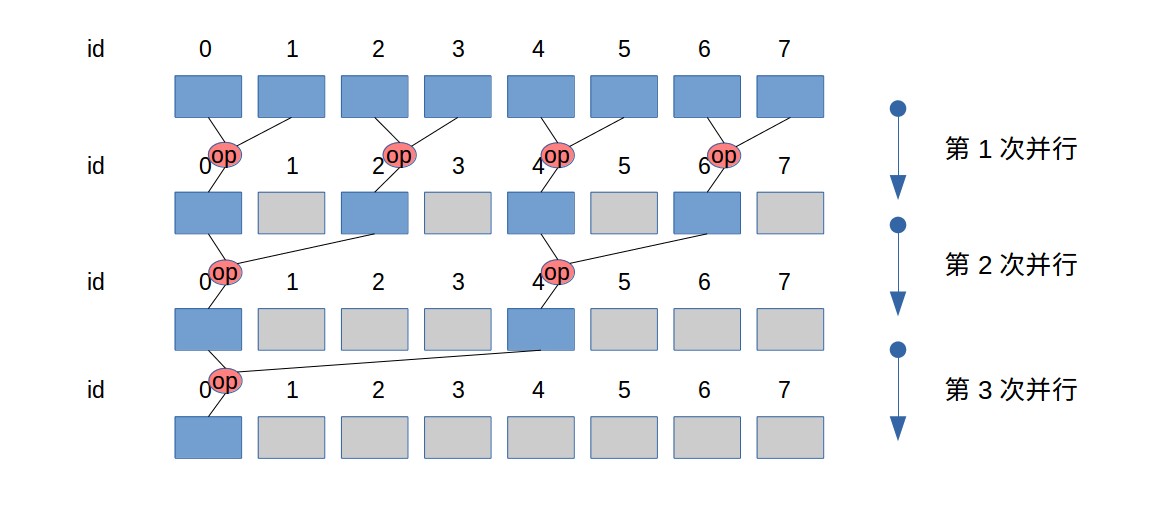
交叉规约
以线程束(warp)为2的情况为例,这种并行规约方法会导致线程束发散(warp deconvergence)。因为线程束是一组在同一时间步中执行相同步骤的线程,所以不同的线程经过条件分支执行不同的指令会导致线程束发散,导致执行效率变低
1 | __global__ func() { |
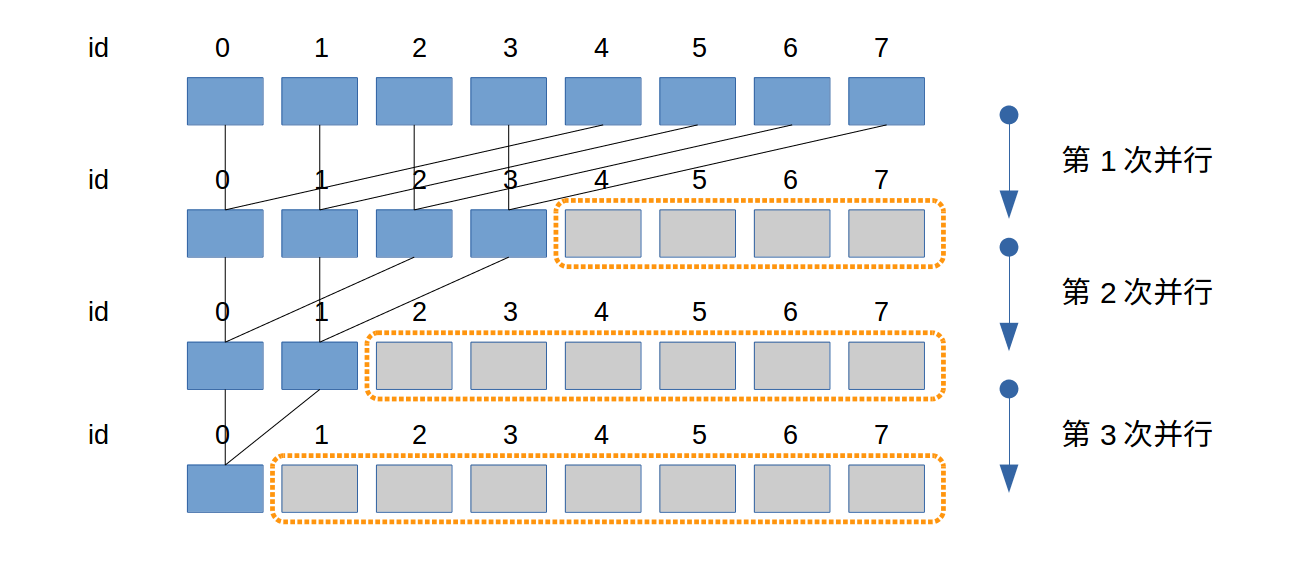
交错规约
该规约方法满足warp运行的特性,当橙色框中存在某一个warp中的所有线程都没有任务时,就可以整体释放资源。当warp=2,该图中所有并行运算都能够提前释放资源
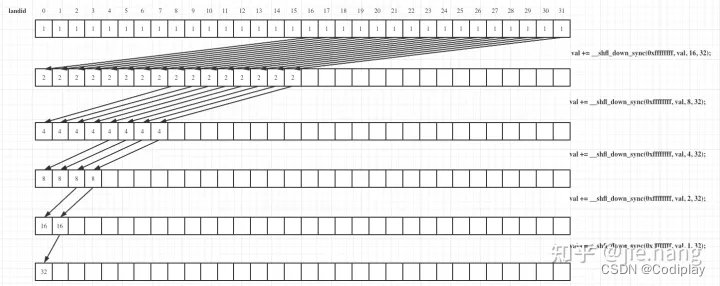
shuffle warp规约
cuda存在内置warp函数,该函数中warp中的线程之间可以高效的交换数据(不使用共享内存,直接通过寄存器)
1 | val += __shfl_down_sync(mask, val, offset, warpSize); |
__shfl_up_sync函数参数和__shfl_down_sync相同,但它是将数据从低索引向高索引的元素上传递